
Introduce RSSM, the model for planning pixel observations
Published:
The Ability to Foresee The Future
Have you ever thought about having a superpower to foresee the future? If you know what will happen when you do something, you definitely can decide your action much more easily. For example, you can avoid an action if you already know it may harm you. Or you can select the best action among the actions you can take. This kind of foresight is not only appealing to humans but also to autonomous agents.
To allow the autonomous agent to move by itself, you can use the reinforcement learning approach. Previously, to get samples which include rewards for training, the agent should interact with the environment. If then, the environment can’t be restored. Even though you realize that the agent performed a bad action (got a low reward), the agent can’t return to the previous step and has to keep moving from the bad state.
However, what if the agent knows what will happen in the next step? Greedily speaking, it can just perform the action that leads to the highest reward. Or if it considers further future, it can simulate many possible routes in the imagination and just follow the route that will give it the highest cumulative reward. This process is called planning.
 For example, planning allows the agent to move through a safer and better path.
For example, planning allows the agent to move through a safer and better path.
Now you know it can be allowed for the autonomous agent to move by planning if it can predict the future. Then, how can it predict the future?
What’s a World Model?
While the definition of the world model is slightly different by literature, generally it includes the transition model (a.k.a. dynamics model) and the reward model.
The transition model predicts how the state of the agent changes after it performs a given action.
The reward model predicts what reward the agent will receive by performing the given action.
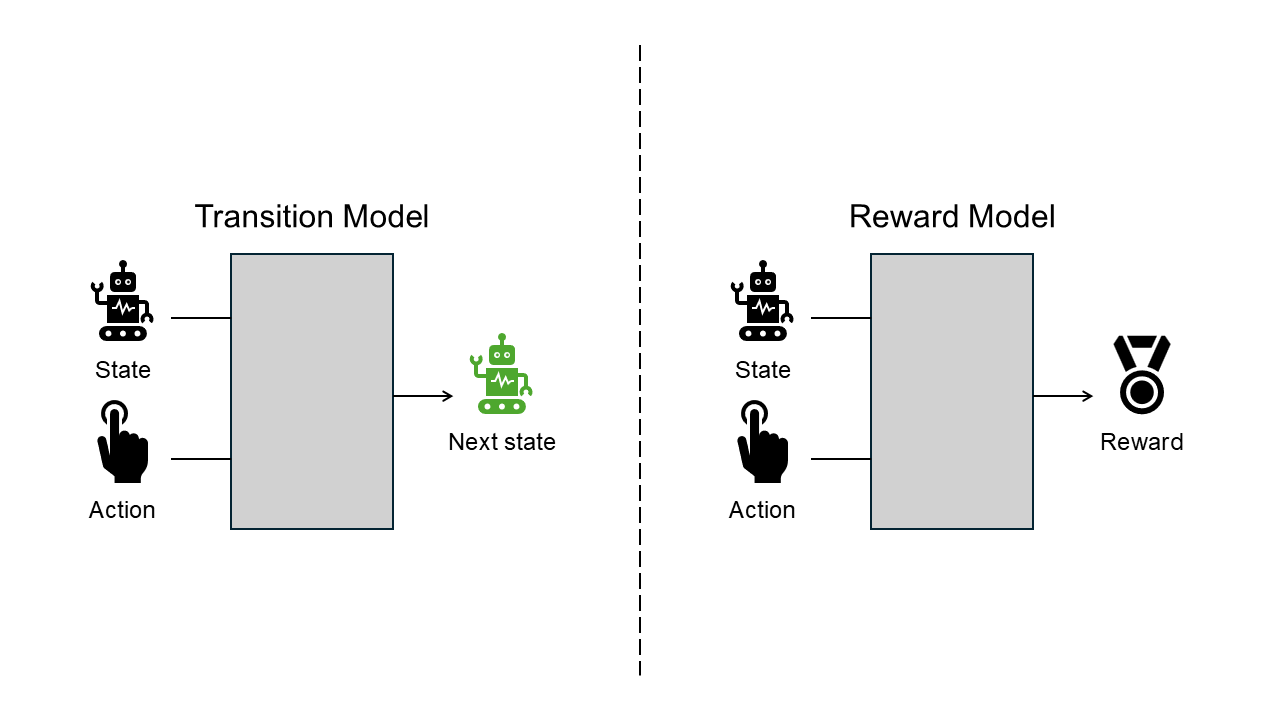 The transition model predicts the future state of the agent through the current state and the action information. The reward model predicts a reward to be received with the same information as the transition model.
The transition model predicts the future state of the agent through the current state and the action information. The reward model predicts a reward to be received with the same information as the transition model.
If the environment is artificial and simple, then it might be easy to manually design the world model. For example, board game environments such as chess make it easy to predict what will happen after performing an action. But in more natural and complex environments like the real world might be hard or even impossible to design manually all transitions and rewards corresponding to every state.
Fortunately, thanks to the rise of deep neural networks, it has been able to train the world model with deep learning methods! But still, the agent needs an accurate world model for planning (especially if it wants to predict farther then the model should be more accurate!). So, many researchers have been trying to train a world model more accurately and also to train a world model of more complex environments.
Nowadays, there are diverse architectures designing the world model. In this post, I would like to introduce one of them, RSSM which uses both stochastic and deterministic latent dynamics models to accurately predict the state from pixel-based observation.
Recurrent State Space Model
As I already mentioned, learning a world model for more complex environments is harder than for a simple one. I will say that pixel-based observation is more complex than knowing the true state due to its high dimensionality and partial observability.
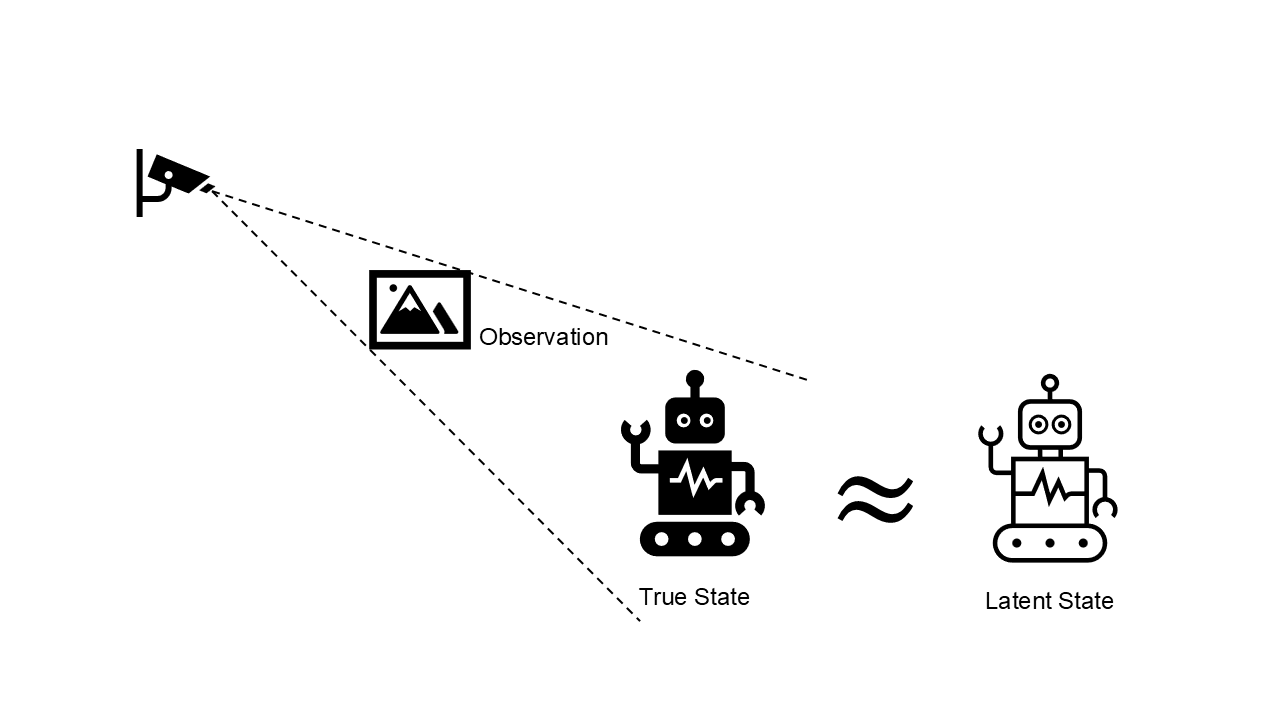 If you observe something with the camera, then you may not be able to capture every information of the true state. Also, the dimension of an image is usually higher than the dimension of the information that you are interested in.
If you observe something with the camera, then you may not be able to capture every information of the true state. Also, the dimension of an image is usually higher than the dimension of the information that you are interested in.
Latent Dynamics Model
To reduce the complexity of the environment even a little bit, an encoder can be used to encode the observations into the latent space and predict the future states in the latent space. This is the concept of the latent dynamics model. Now the agent needs two more models to build a world model. One is the encoder which encodes the observations to the latent states, and the other one is the observation model which predicts the observation with the latent state.
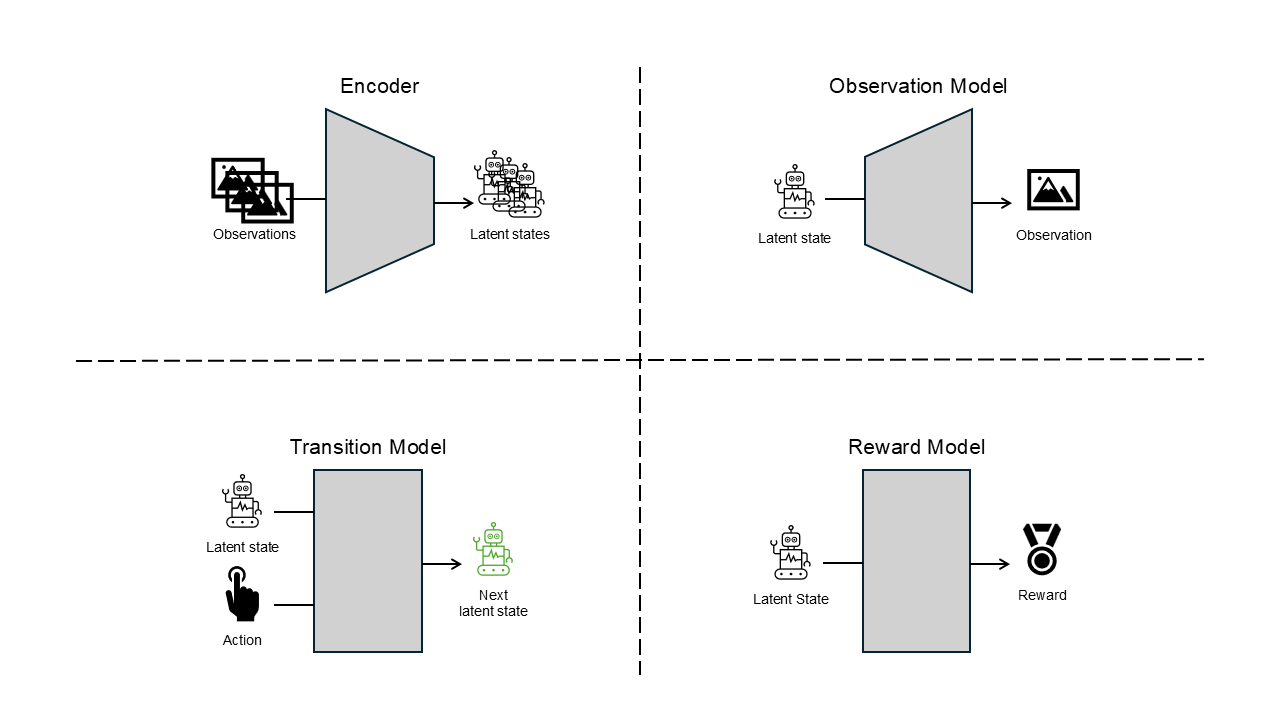 The encoder encodes the observations into the latent states, and the observation model acts a role as a kind of decoder
The encoder encodes the observations into the latent states, and the observation model acts a role as a kind of decoder
Sequential Model
To approximate the latent state as closely as the true state, the agent can use the information of the state in history. Since the agent’s states are sequential in terms of time, it can be considered to use the sequential model to build a world model.
Generally, the environment would not be deterministic. It means that even though the agent performs the same action in the same state, there is a probability of leading it to a different state. So, It’s more natural that the transition model predicts the probability of the next state than predicts the next state directly.
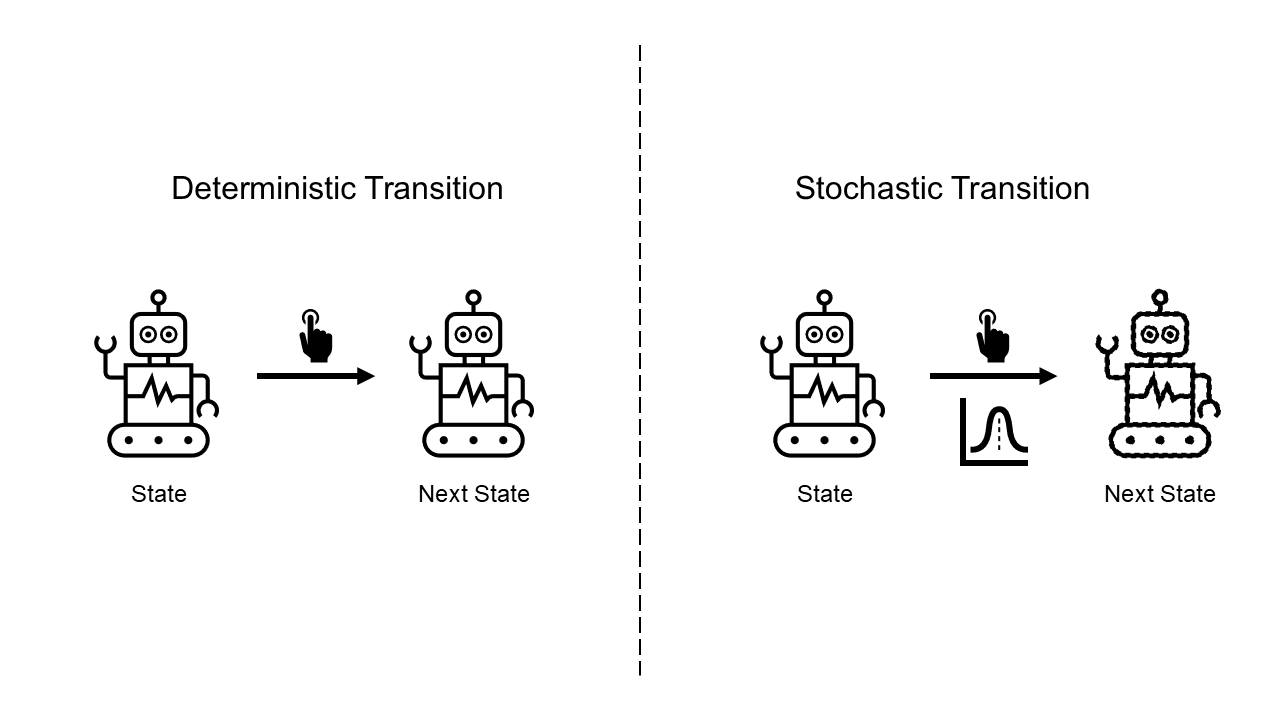 If the transition model is deterministic, then it will predict always the same transition, on the other hand, if the transition model is stochastic, then it will predict the probability of the next states.
If the transition model is deterministic, then it will predict always the same transition, on the other hand, if the transition model is stochastic, then it will predict the probability of the next states.
However, if the sequential model uses the stochastic transition model to predict their next state, it may lose the old information during the transitions. If then, it’ll be hard to predict the long-term future and also hard to make a long-term plan. But if the sequential model uses only the deterministic model, it won’t be able to represent the stochasticity of the environment.

RSSM uses both stochastic and deterministic transition models to mitigate this limitation. It can predict further states more accurately than stochastic or deterministic models.

PlaNet
By using this RSSM, the authors proposed the deep planning network called PlaNet. PlaNet generates multiple plannings by RSSM, selects the best one, and performs the first action of the plan. And iterate the process. The below image roughly shows how PlaNet selects the action.

Recent Works
There are also other algorithms using RSSM as a world model. They are the Dreamer series and Director. Dreamer improves the performance of agents via training a policy network with imagined data generated by the world model, and Director hierarchically trains two policies to tackle longer and more complex tasks. I’m looking forward to introducing these algorithms someday.
Caution
This blog post excludes many details and formulas to deliver the higher-level concept in an easy way. If you are interested in this content, please check the original paper to fully understand the whole information.